

GPU·NPU 분리형 추론 적용…에너지 32% 절감, 지연 89% 감소
인공지능(AI) 경량화 및 최적화 기술 기업 노타가 AI PC 환경에서 그래픽처리장치(GPU)와 신경망처리장치(NPU)를 동시에 활용하는 이기종 컴퓨팅 기반 거대언어모델(LLM) 추론 최적화 기술을 성공적으로 구현했다. 단일 프로세서의 사양에만 의존하는 기존 방식에서 벗어나 시스템 전체의 연산 자원을 효율적으로 배분함으로써 온디바이스 AI의 사용자 경험을 획기적으로 개선한다는 전략이다.
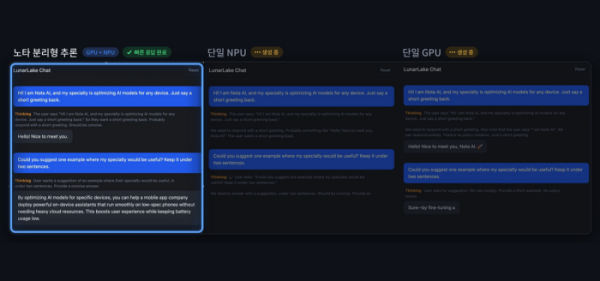
노타는 인텔의 루나 레이크 기반 AI PC에서 LLM의 실행 과정을 입력 처리와 답변 생성 단계로 나눠 분석하고, 각 단계의 연산 특성에 맞게 장치를 분산 배치하는 ‘분리형 추론’ 방식을 적용했다고 4일 밝혔다. 이에 따라 대용량 계산이 필요한 입력 처리 연산은 GPU에, 지속적인 답변 생성 연산은 NPU에서 실행되도록 하드웨어 구조를 최적화했다.
실제 성능 평가 결과, 노타의 분리형 추론 방식은 단일 GPU 실행 방식과 비교해 토큰당 에너지 소비를 약 32% 절감하고, 생성 처리량을 약 12% 향상시켰다. 아울러 단일 NPU 구동 방식 대비 첫 응답 지연시간을 약 89%나 단축하는 성과를 거뒀다. 제한된 전력과 연산 자원을 사용하는 AI PC 환경에서 하드웨어 활용 방식을 바꾸는 것만으로도 구동 효율성을 극대화할 수 있음을 증명한 셈이다.
최근 글로벌 빅테크 기업들을 중심으로 AI PC 시장 내 이기종 컴퓨팅 흐름이 급속도로 확산되고 있다. 대만에서 열린 ‘컴퓨텍스 2026’에서도 중앙처리장치(CPU), GPU, NPU를 결합한 AI PC가 대거 등장했으며, 엔비디아와 아마존웹서비스(AWS) 등도 데이터센터에 분리형 추론 방식을 도입하는 추세다. 노타는 이번 기술을 통해 단순 모델 경량화를 넘어 시스템 전체의 효율을 다듬는 기술 역량을 입증했다.
채명수 노타 대표는 “AI PC 시대에는 AI 모델을 기기 안에 올리는 것만으로는 충분하지 않으며 GPU, NPU 등 다양한 연산 장치를 모델 특성에 맞게 조합하는 최적화 역량이 실제 AI 경험을 좌우한다”라며 “노타는 모델 경량화, 런타임 최적화, 하드웨어 최적화 기술을 결합해 AI PC 시대의 온디바이스 AI 실행 효율을 높여 나가겠다”라고 밝혔다.



